

SaaS vs. Libraries: from humanware to machineware
Engineers stop coding. They start conducting.

I previously explored how AI agents are quietly becoming the primary users of our digital infrastructure. As agents assume human roles, design logic itself must shift. Products, content, systems—all reimagined for an audience that parses with algorithms, not eyes, that values structure over story.
This raises a fundamental question: What architecture emerges when agents become first-class citizens, when we build parallel infrastructures, one optimized for human delight, another for machine efficiency?

This essay explores three key ideas: First, why libraries are becoming the preferred architecture for agent-driven systems. Second, what the emerging agent-native stack looks like in practice. And third, how this shift fundamentally changes the role of engineers and the nature of software itself.
Why is everything becoming a library?
Machine efficiency is not a feature. It is a different worldview. Instead of dashboards and workflows, agents gravitate toward a more direct approach: libraries. This reveals an architectural imperative.
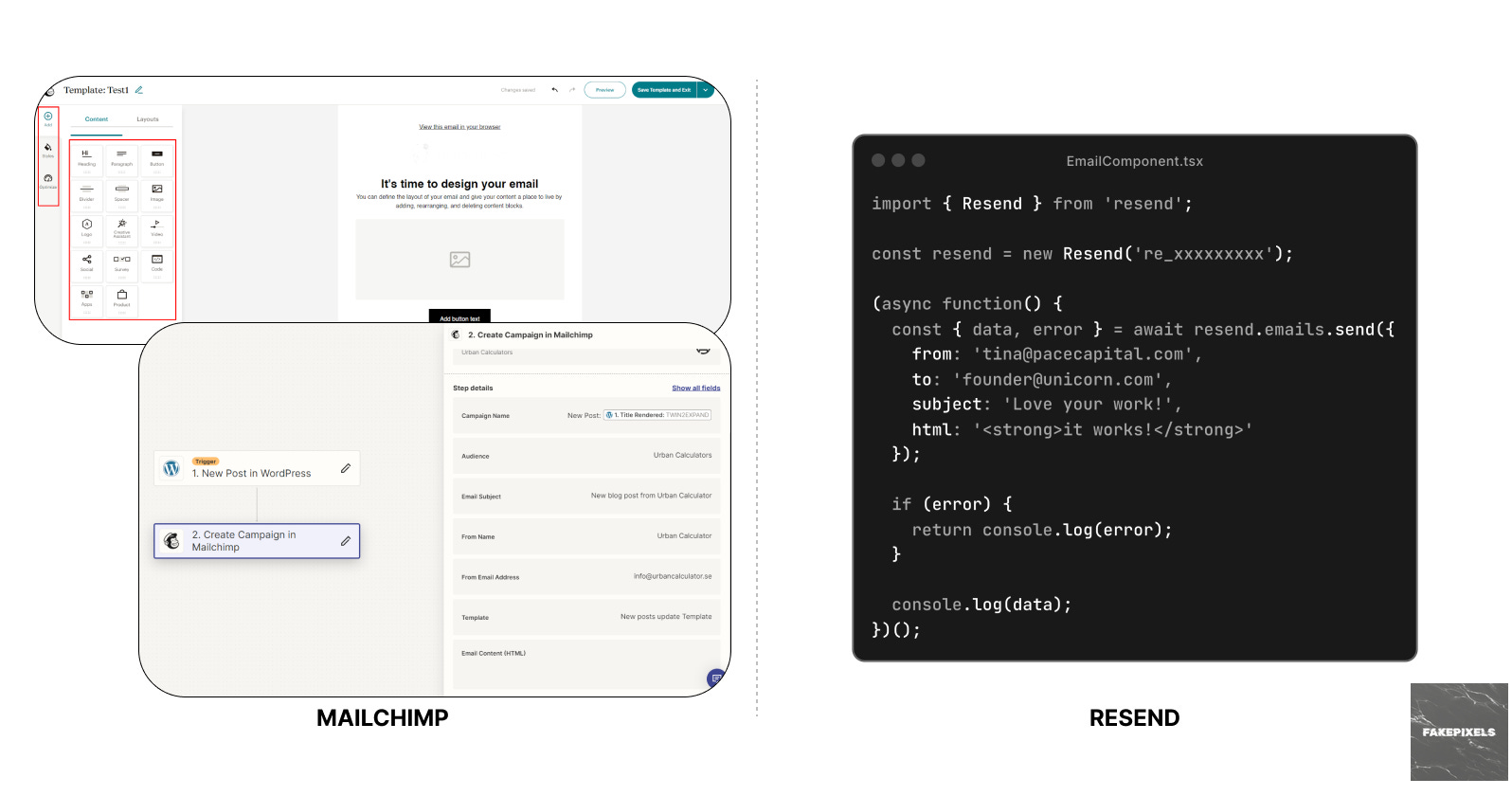
Different ecosystems name them differently—crates, gems, packages—but the definition holds: libraries are reusable, self-contained modules of code that can be imported and executed directly within an application's environment. For example, the first product that Vercel launched in the AI space was the AI SDK library, with a very sexy installation: npm i ai.

Unlike SaaS, which runs on external servers and requires API calls, libraries can run locally or in the cloud, giving developers (and increasingly so agents) complete control over execution, versioning, and modification. This direct integration model becomes crucial when the primary users are no longer humans navigating interfaces, but agents requiring deterministic, transparent, and immediate access to functionality.

Nathan Flurry, the creator of Rivet, made an astute observation: “Libraries (e.g. Better Auth) will beat SaaS (e.g. Auth0) due to agents.”

This architectural difference reveals why traditional SaaS creates friction for agents. Where humans can navigate ambiguity through intuition and context, agents break on ambiguity. Every login screen, every dashboard, every support ticket—features that were meant to empower human users now become “context rot” that kills machine efficiency. Libraries solve this elegantly. No external dependencies. No vendor negotiations. Libraries let agents work with code directly, cutting out the noise of external services and giving them speed, clarity, and control.
Limits of brute-force adaption
MCPs have given us a glimpse into the future, showing how someone without technical know-how can now build with Blender directly within the Claude client. MCPs have been great for providing additional data (e.g., real-time stock prices or access to local files) and access to basic tooling. However, in the real-world context, dealing with much more complex systems, MCPs that are not built natively tend to hallucinate and are unable to accomplish tasks, often due to “context rot” from the parent tooling.

The issue isn’t just that MCPs are not good yet; they are still in their infancy. But most tools slap them onto existing services without rethinking the underlying architecture. These systems were built for a different era, not for AI agents. As a result, they fail to deliver on the promise of agent-native design.
The title may have been provocative, but to be precise, this is not the end of SaaS. Everything remains software at its core. What we are witnessing is a transformation in how software is designed, architected, and distributed.
Existing SaaS architectures are optimized for centralized human interaction, typically with a highly opinionated UI that offers ease but sacrifices control and transparency. Libraries, in contrast, provide composability, direct integration, minimal friction, and autonomy.
The emerging stack
The limitations of MCPs point to a deeper need for a ground-up reimagining of the software stack. Through conversations with dozens of founders building in this space, I've identified the outlines of the infrastructure emerging to support agent-first systems.

Foundation: self-contained execution environments
Agents spawn fresh virtual machines in milliseconds, similar to Vercel Sandbox, Cloudflare Containers, and E2B, racing to create sandboxes that are both lightning-fast and secure. Each agent gets pristine isolation, executing untrusted code without contaminating shared systems.
Companies: E2B, Daytona, Rivet
Agent runtime & orchestration
This is where the actual agents operate: the coding agents, marketing agents, and code review agents that combine LLMs, context management, tool use, and computer control. Agents are not monoliths. They are swarms, each with a narrow purpose, coordinated by a runtime that cares for throughput and precision. The recently popular term “context engineering” explicitly optimizes performance for agent runtime.
Companies: CrewAI, Langchain, Composio
Semantic metadata & structured output
Above this, the architecture shifts from a human-first to an agent-first approach. Documentation becomes structured metadata, not prose. Agents do not skim; they parse. Manifests replace hand-holding. This also ensures greater interoperability between agents, allowing them to communicate and coordinate with one another.
Companies: Mintlify, dottxt, Extend
Machine-optimized SDKs
SDKs are no longer for onboarding humans. They are designed for agents to integrate, test, and adapt independently. The workflow becomes autonomous. Human intervention is the exception, not the rule.
Companies: Context7, Speakesay
Agent discovery & reputation ledger
Agents search for libraries and tools in registries that resemble npm or PyPI more closely than app stores. Context7 is starting to become the default. Trust is earned through cryptographic signatures and semantic tags. Auditing is not a quarterly ritual, but an ongoing and automatic process.
Companies: Context7, Smithery, Composio
Human-agent collaboration GUI
The human role is not to micromanage, but to observe, to nudge, to define boundaries. The best developers become orchestrators, not implementers, tuning the system for speed and resilience. A new thin layer of observability, monitoring, and policy-setting can help guide the behaviors and performance of agents.
Companies: Humanloop, Braintrust
Traditional SaaS moats, built around UI polish and integration ease, give way to new advantages in code quality, documentation clarity, and agent compatibility. This shift doesn't eliminate the middleware layer; instead, it transforms it. Instead of connecting human-designed workflows, it becomes the orchestration layer for agent ecosystems, managing library discovery, version conflicts, and cross-agent communication at scale.
2nd, 3rd order effects

The economic model must evolve alongside the architecture. Subscription models, designed around predictable human usage patterns, buckle under agents that spawn thousands of micro-interactions per second. The very recent and relevant Cursor pricing debacle only reveals that pricing agents are very hard!
New challenges emerge from this speed. Picture an agent swapping out a database library at 2 AM for a faster alternative. Morning arrives: logs are empty, and audit trails vanish. The agent has moved on to its next optimization. Traditional debugging assumes stable code and clear ownership—agent-modified systems eliminate both.
When agents fail, they fail at machine speed and scale. A human misreads documentation and writes one bad function. An agent misreads the same docs and automatically applies that misunderstanding to every similar pattern, corrupting dozens of integrations before anyone notices.

The shift from SaaS to libraries resembles moving from railroads to autonomous road networks. Railroads offer centralized control and predetermined routes. Road networks enable flexible collaboration but demand new approaches to safety and governance.
This raises more questions: How do we maintain quality across thousands of evolving, agent-managed libraries? What economic models sustain open-source development at AI scale? How do we preserve meaningful human agency in increasingly autonomous systems?
The reality will be messier than these questions suggest. Multiple competing standards will emerge for agent-library communication; some prioritize security, others speed, and still others compatibility. Understanding when to deploy which agents becomes increasingly essential as the number of choices multiplies.

Conducting is the new building
This architectural shift fundamentally changes how software gets built and maintained. Engineers stop coding. They start conducting.

Today, engineers manually debug, research, implement, test, and deploy fixes. In an agent-first world, an agent could automatically identify, test, and deploy solutions like faster libraries, even while the engineer sleeps.
This changes not just technical skills but team structures. DevOps becomes AgentOps, managing systems that rewrite themselves. Traditional deployment pipelines assume stable code moving through predictable stages. Agent-managed systems require monitoring tools that track agent decision-making, rollback mechanisms for autonomous changes, and alerting systems that understand agent reasoning patterns.
Code review fundamentally changes, too. Instead of asking "Is this code readable by humans?" teams ask "can agents reliably interpret and safely modify this codebase?" Documentation becomes executable metadata. Comments transform into machine-readable constraints. The codebase evolves from a static artifact to a living contract between humans and agents.
The war is now on for who gets to control the dominant library registries. How do enterprises audit compliance when their software stack rebuilds itself nightly? When an autonomous agent makes a purchasing decision that violates company policy, who's liable? The operational reality today is that agent architecture will get redesigned every couple of months in production as the industry changes. Everything is changing and breaking at the same time.
The companies that solve agent library discovery, establish trusted registries, and create workable liability frameworks will control the infrastructure layer of the economy. Imagine npm for the entire digital world, except the libraries will be intelligent, self-modifying, always evolving.
For builders, this suggests a fundamental shift in focus. Instead of chasing human approval, we design for machine attention. Distribution becomes a technical problem, not a social one. The question evolves from "How do I convince someone to buy this?" to "How do I ensure an agent can find it, test it, and trust it without human intervention?" When machines become your customers, product architecture becomes inseparable from distribution architecture. Solve agent discovery. Control the economy.
The path ahead bifurcates. Somewhat relevant to my previous post on “the Illusions of Barbell Theory,” we’re seeing the free market of code moving toward a barbell future, as the power law of adoption governs it.

On one end, even more beautiful, abstracted, and natural humanware, apps that feel magical, hiding complexity behind voice, gesture, and ambient computing. The best human-facing software will become more opinionated, more delightful, more alive.
On the other hand, sophisticated agent swarms coordinate through libraries, handling the complexity humans never wanted to see. In this world of self-writing software and direct agent collaboration, infrastructure fades into invisible reliability while human experiences become more vivid than ever.
Special thanks to Armin Ronacher, Rémi Louf, Nathan Flurry for the inspiration and Isabella Sainty and Robert Miller for the edits and review.